
”深度学习 transformer“ 的搜索结果

深度学习-一些关于transformer解读ppt

详细解释了transformer架构相关知识
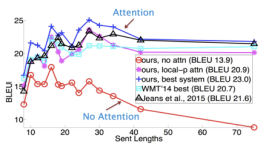
transformer在NeurIPS2017诞生,用于英语-德语,英语-法语的翻译,在BLEU(bilingual evaluation understudy)指标上得到了很好的表现。由自然语言生成代码也是一种翻译,文生图也是一种转换,事实上chatgpt,bert都是...

深度学习-Transformer实战系列视频教程,2022新课,目前市面上为数不多的关于Transformer的课程,希望对大家的学习有所帮助

最近在做论文,需要使用transformer模型进行时间序列数据的预测。目前matlab深度学习工具箱中好像没有这个模块?本人不会写代码,请问有什么第三方的工具箱或者其他解决方案吗? 感谢各位!!

学习Transformer之前我们先看一下作者论文中的模型,如下图所示:本章内容主要是自己学习笔记,在学习过程中总结和整理,希望对各位有所帮助。本章学习从基础模型 Transformer 拆解,分析整个 Transformer 架构用到...
https://blog.csdn.net/z0816208/article/details/137792765?spm=1001.2014.3001.5502

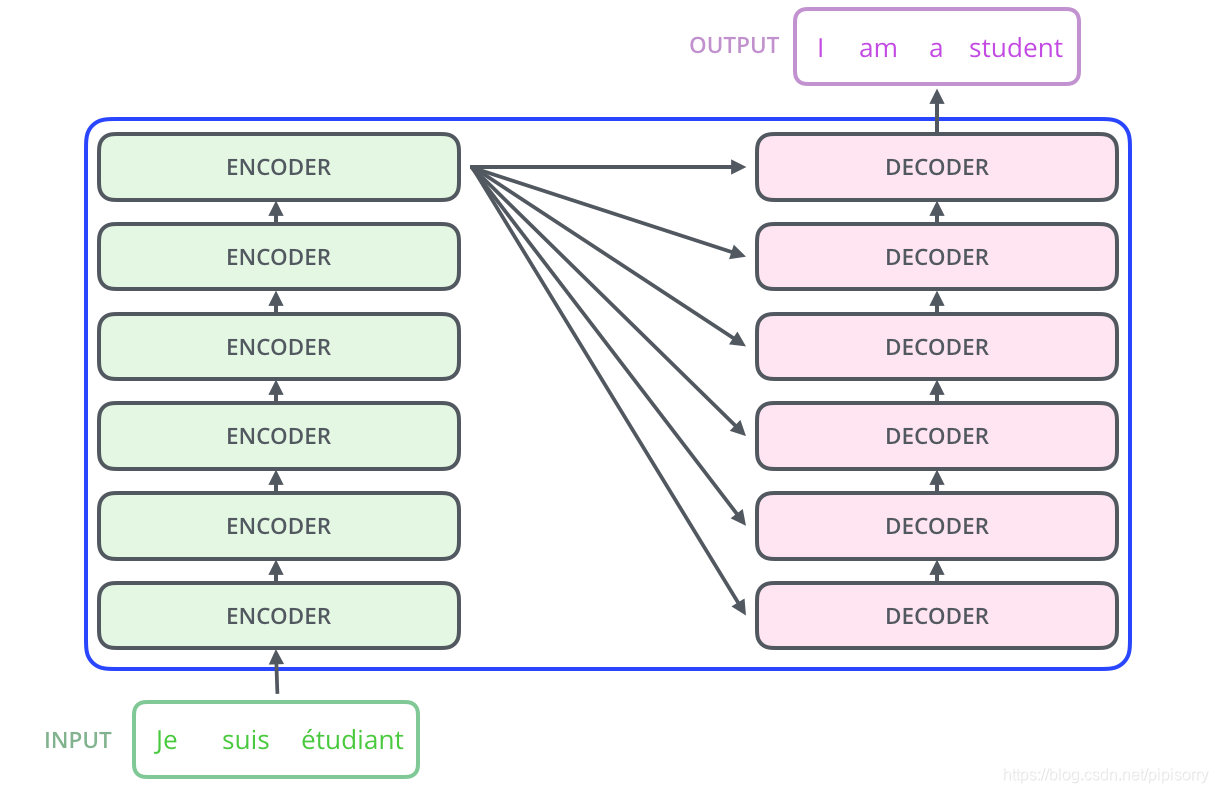
Transformer是一个Seq2Seq(Sequence-to-Sequence)的模型,这意味着它能够处理从输入序列到输出序列的问题。在Seq2Seq模型中,输入是一段序列,输出也是一段序列,输出序列的长度通常由模型自身决定。这种模型在...
Transformer在深度学习环境下背景: 17年自Attention is all you need提出后,开始在NLP(自然语言处理)领域大放异彩 20年后,开始在CV领域发光,到现在基本一统天下了 其在NLP和CV领域下的许多分类、分割、检测等...
深度学习——Transformer的理解整理
UniFormer:深度学习中的统一Transformer模型框架 项目地址:https://gitcode.com/Sense-X/UniFormer 本文将向您推荐一个创新的深度学习项目——UniFormer。这是一个由SenseTime团队开发的开源项目,旨在提供一种高效...
深度学习自然语言处理-Transformer模型.zip
Vision Transformer (ViT) 结构简介
瓶颈Transformer:PyTorch实现的新颖深度学习模型 项目简介 项目地址:https://gitcode.com/lucidrains/bottleneck-transformer-pytorch Bottleneck Transformer 是一个由LucidRains开发的开源项目,它提供了一个基于...

探索Transformer-TensorFlow:深度学习的新里程碑 项目地址:https://gitcode.com/lilianweng/transformer-tensorflow Transformer-TensorFlow是一个基于TensorFlow实现的Transformer模型,由著名AI研究者Lilian Weng...
精通CNN、RNN、Transformer是成为一名优秀Python深度学习工程师的关键。深入理解上述常见问题、易错点及应对策略,结合实际代码示例,您将在面试中展现出扎实的深度学习模型基础和出色的模型构建能力。持续实践与...
最近神经网络结构Transformer非常流行,先后席卷了NLP和CV,大有取代CNN一统天下之势。 Transformer中文名是变形金刚的意思。
作者:禅与计算机程序设计艺术 《深度学习中的 Transformer 应用》 1. 引言 随着深度学习技术的快速发展,Transformer 模型的出现
3.Transformer模型 3.1.CNN与RNN的缺点: 1.CNNs 易于并行化,却不适合捕捉变长序列内的依赖关系。 2.RNNs 适合捕捉长距离变长序列的依赖,但是却难以实现并行化处理序列 3.2.为了整合CNN和RNN的优势,创新性地使用...
我们可以看到,一旦输入句子(原句),编码器就会学习其特征并将特征发送给解码器,而解码器又会生成输出句(目标句)。[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.[3] ...
推荐文章
- 阿里云企业邮箱的stmp服务器地址_阿里云stmp地址-程序员宅基地
- c++ 判断数学表达式有效性_高考数学大题如何"保分"?学霸教你六大绝招!...-程序员宅基地
- 处理office365登录出现服务器问题_o365登陆显示网络异常-程序员宅基地
- Nginx RTMP源码分析--ngx_rtmp_live_module源码分析之添加stream_ngx_rtmp_live_module 原理-程序员宅基地
- 基于Ansible+Python开发运维巡检工具_automation_inspector.tar.gz-程序员宅基地
- Linux Shell - if 语句和判断表达式_shell if elif-程序员宅基地
- python升序和降序排序_Python排序列表数组方法–通过示例解释升序和降序-程序员宅基地
- jenkins 构建前执行shell_Jenkins – 在构建之前执行脚本,然后让用户确认构建-程序员宅基地
- 如何完全卸载MySQL_mysql怎么卸载干净-程序员宅基地
- AndroidO Treble架构下HIDL服务查询过程_found dead hwbinder service-程序员宅基地